Genomics Data Standardization with FHIR
Translational medicine and precision medicine involve combining clinical and genomic data to derive actionable insights that can be applied at the point of care. Typically, clinical and genomics data come from different sources: clinical data come from systems like electronic health records, laboratory information systems, and other specialty clinical systems, while genomics data are often sourced directly from the bioinformatics data pipelines responsible for processing source data from DNA sequencing machines.
Developing combined clinical+genomics datasets is currently challenging because there are not widely adopted exchange standards that cover both clinical and genomic data. In their absence, bespoke structural and semantic mappings may be used, which limits reuse and scaling. This is also complicated by the “big data” challenges associated with genomic data due to its breadth and depth: a single human genome ranges from hundreds of megabytes to gigabytes in size, which is larger than most clinical datasets for all patients in a study.
1 Why FHIR for genomics standardization?
FHIR provides a cohesive framework for developing a standardized genomic learning health system. It proposes extensible and modular information models, operations, and tooling needed for the exchange and processing of clinical and genomic data.
The HL7 genomics community aspires to address the entire clinical genomics data flow, from ordering to results reporting to evidence generation. This is possible because of the breadth of the HL7 community which has dedicated and collaborative working groups that address each part of the flow.
2 HL7 genomics-related FHIR specifications
2.1 FHIR Genomics Reporting Implementation Guide (GRIG)
The HL7 FHIR Genomics Reporting Implementation Guide (GRIG) provides guidance for a standardized representation of genomics data elements leveraging the FHIR framework of resources and operations, optimized for the genomic data exchange for clinical and research-oriented genomic use cases. The GRIG is a HL7 project under the HL7 Clinical Genomics Workgroup (CGWG).
The GRIG is very broad in that it tries to meet both the provider and research needs, covering many aspects of genomics reporting, including:
- Representation of simple discrete variants, structural variants including copy number variants, complex variants as well as gross variations such as extra or missing chromosomes
- Representation of both known variants as well as fully describing de novo variations
- Germline and somatic variations
- Relevance of identified variations from the perspective of disease pathology, pharmacogenomics, transplant suitability (e.g., HLA typing), etc.
- Full and partial DNA sequencing, including whole genome and exome studies
A high-level diagram summarizing the general FHIR genomics constructs in the GRIG is shown below:
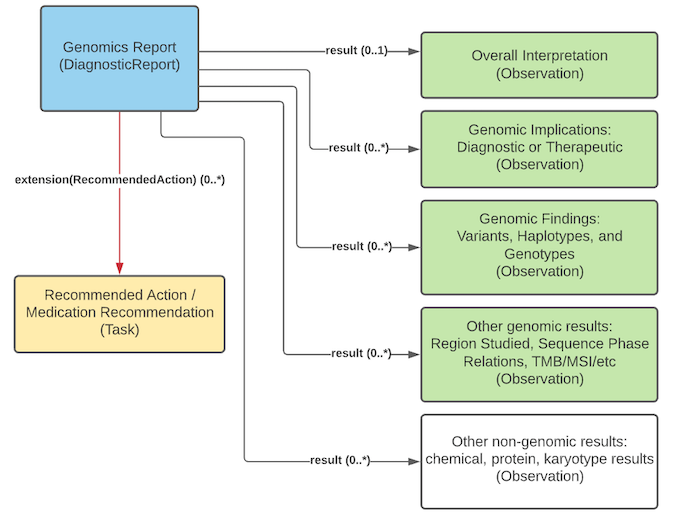
An artifact index summarizes the genomics-related constructs including information modeling diagrams, FHIR profiles, example FHIR resources for each profile, and additional guidance on searching for genomic-related FHIR resources through 1) standard FHIR search parameters, and 2) FHIR operations that are tailored for bioinformatic tasks.
FHIR genomic operations include but are not limited to:
normalization services
dynamic diagnostic or therapeutic implications based on a patient’s variants
retrieving cohorts of patients with specific variants, phenotypes, genotypes, study metadata
Note: full specification of FHIR genomic operations are in development with a target ballot date in early 2024.
2.2 Genomic base FHIR resources
The focus of the GRIG is on genomics reporting that mostly occurs after annotation and interpretation in a bioinformatics pipeline. There are however additional research-driven needs for more granular data which merited the release of FHIR base resources. These include:
MolecularSequence - designed for representing molecular sequences. This resource is not be used for other entities such as variant, variant annotations, genotypes, haplotypes, etc. Those entities will be captured in Observation profiles found in the Genomics Reporting Implementation Guide.
GenomicStudy - New with FHIR 5.0, the GenomicStudy resource specifies relevant information found in a genomic study, which includes one or more analyses, each serving a specific purpose. These analyses may vary in method (e.g., karyotyping, CNV, or SNV detection), performer, software, devices used, or regions targeted. The use of this resource differs from the Genomics Report profile from the GRIG in that detailed information about the results of the analyses in GenomicStudy may be represented by Observations and gathered in a DiagnosticReport. Both resources may refer back to the originating GenomicStudy to allow navigation.
2.3 minimum Common Oncology Data Elements (mCODE)
mCODE is a FHIR specification for a minimal and actionable set of cancer data elements. mCODE includes relevant genomic elements since much of cancer research and care is dependent on genomics for disease discovery and therapeutic decision making.
The mCODE standards specifications team works closely with the HL7 CGWG to ensure alignment between mCODE FHIR IG and the GRIG.
2.4 Phenopackets
The Global Alliance for Genomics and Health (GA4GH) Phenopacket standard is not a native FHIR-based standard. Rather it is a lightweight specification that intends to support global exchange of computable case-level phenotypic information for all types of disease diagnosis and research. However, the specification was ported to a GA4GH Phenopacket FHIR Implementation Guide and is currently under development. The Phenopackets designers are working closely with the CCWG to align both standards.
3 Relevant FHIR Tools
3.1 VCF to FHIR
vcf2fhir is a utility which converts VCF files into HL7 FHIR format, conforming to the HL7 FHIR GRIG. It is open-sourced and available on GitHub.
4 Engaging with the FHIR genomics community
4.1 HL7 Clinical Genomics Working Group
The HL7 Clinical Genomics Workgroup (CGWG) comprise of a diverse community of researchers, providers, and non-profit specialty organizations primarily focused standards development that supports the semantically meaningful exchange of data between parties interested in clinical, personal, and population genomic information and family health history.
CGWG is is the author and steward of the FHIR Genomics Reporting Implementation Guide (discussed above), a FHIR-based specification for the exchange of genomics reporting elements.
4.2 CodeX FHIR Accelerator domain: GenomeX
GenomeX is a domain use case under the HL7 CodeX FHIR Accelerator. GenomeX consists of a multi-stakeholder community, working together as subject matter experts, to enable high-quality, computable data for the genomics ecosystem. The community aims to ensure that the genomics FHIR-based specifications meet the needs of stakeholders as validated through real-world pilots in designated use cases.
The multi-stakeholder community represents a broad spectrum involved in genomic message and data exchange with representatives that include genomic reference labs, EHR vendors, provider organizations, life sciences, analytic and decision support platforms, and non-profit organizations and consortiums.
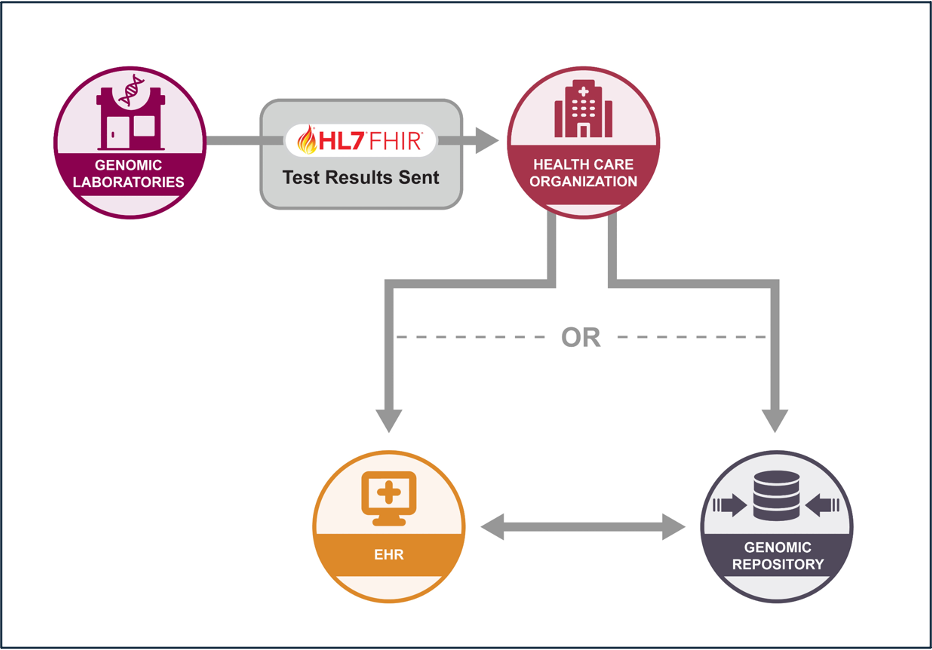
Through consensus, GenomeX stakeholders bring a real-world implementation focus in two use cases identified in the development of an integrated and standardized genomics solution in two major areas:
Standardizing the data exchange of genomic reports from a reference lab to a clinical application.
Standardizing the message exchange and access of genomic data between a genomic repository and consuming applications through FHIR-based operations.
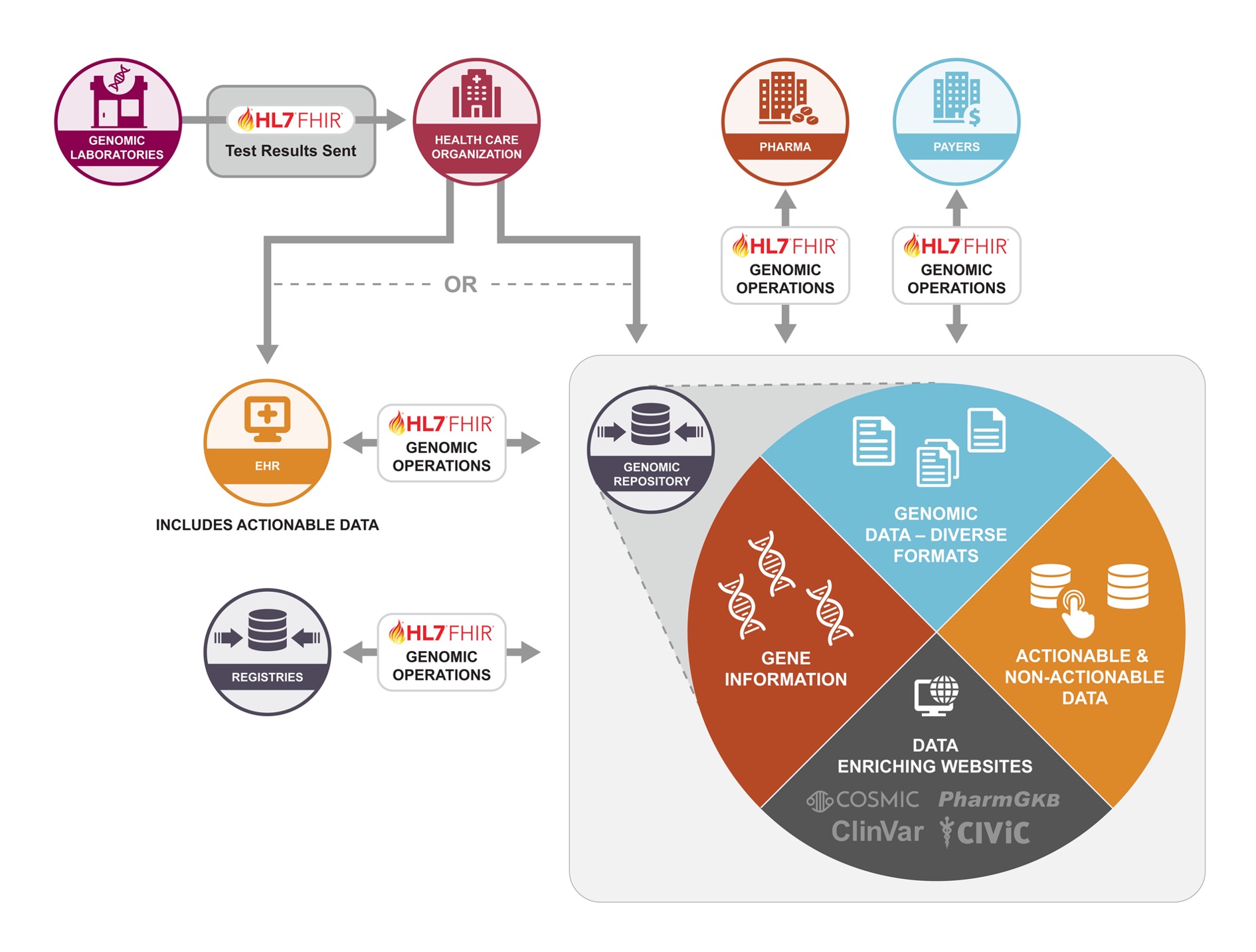
The GenomeX community works closely with the HL7 CGWG as a validator and influencer of the existing FHIR specifications through real-world implementations.